so-large-lm | Day 2~3
大模型基础 | Day 2~3
好像是一个LLM的入门讲解捏
新的模型架构
混合专家
- 混合专家模型:我们创建一组专家。每个输入只激活一小部分专家。
- 直觉:类似一个由专家组成的咨询委员会,每个人都有不同的背景(如历史、数学、科学等)。
$$
\text{input} \quad\quad\Rightarrow\quad\quad \text{expert}_1 \quad \text{expert}_2 \quad \text{expert}_3 \quad \text{expert}_4 \quad\quad\Rightarrow\quad\quad \text{output}.
$$
Sparsely-gated mixture of experts (Lepikhin et al. 2021)
- 因此,我们将混合专家的想法应用于:
- 每个token
- 每层Transformer block(或者隔层使用)
- 由于前馈层对于每个token是独立的,因此,我们将每个前馈网络转变为混合专家(MoE)前馈网络:
$$
\text{MoETransformerBlock}(x_{1:L}) = \text{AddNorm}(\text{MoEFeedForward}, \text{AddNorm}(\text{SelfAttention}, x_{1:L})).
$$
- 隔层使用MoE Transformer block。
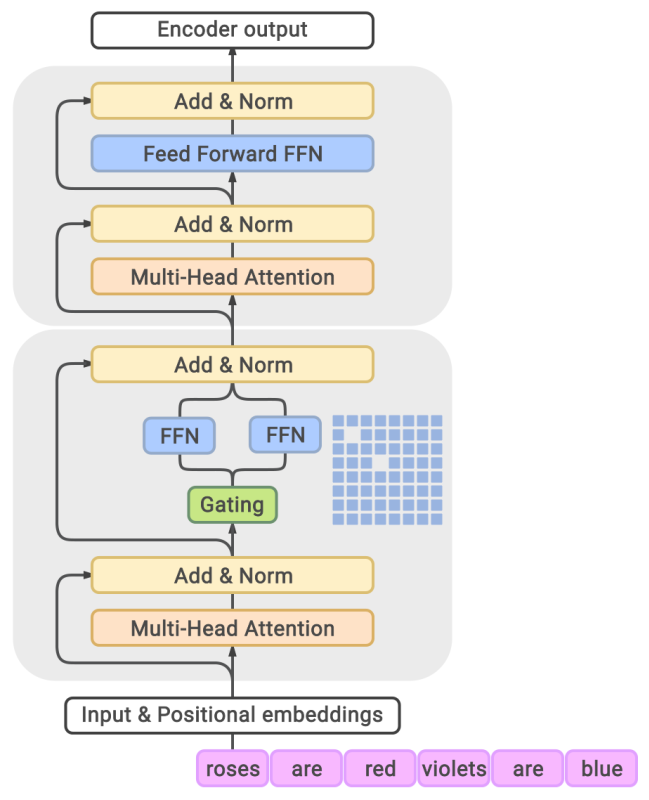
我们将top-2专家的近似门控函数定义如下:
计算第一个专家: $e_1 = \arg\max_e g_e(x)$ 。
计算第二个专家: $e_2 = \arg\max_{e \neq e_1} g_e(x)$ 。
始终保留第一个专家,并随机保留第二个专家:
- 设 $p = \min(2 g_{e_2}(x), 1)$
- 在概率为 $p$ 的情况下, $\tilde g_{e_1}(x) = \frac{g_{e_1}(x)}{g_{e_1}(x) + g_{e_2}(x)}, \tilde g_{e_2}(x) = \frac{g_{e_2}(x)}{g_{e_1}(x) + g_{e_2}(x)}$ 。对于其他专家 $e \not\in { e_1, e_2 }$,$\tilde g_e(x) = 0$ 。
- 在概率为 $1 - p$ 的情况下, $\tilde g_{e_1}(x) = 1$。对于$e \neq e_1$,$\tilde g_e(x) = 0 $ 。
这里感觉需要多沉淀一下捏,后面应该会专门开一篇来学一下混合专家捏
基于检索的模型
就是RAG起手的吧,这又是一大坨了捏
LLMs 的数据
就是介绍了一下常用的文本数据集捏
模型训练
从两个角度来看模型训练:目标函数和优化算法
目标函数
Decoder-only 模型
最大似然就可以了捏
Encoder-only 模型
鼠鼠想下班了捏
BERT
由于BERT最初的构想是做一个可迁移的通用模型,所以在任务上也是分作两个的:
- Masked language modeling:完形填空捏
- Next sentence prediction:判断一个🍊是不是另一个🍊的下一句捏
所以具体来说,他的loss就是
$$
\mathcal{O}(\theta)=\sum_{\left(x_{1: L} c\right) \in \mathcal{D}} \underbrace{\mathbb{E}_{I, \tilde{x}_{1: L} \sim A\left(\cdot \mid x_{1: L} I\right)}\left[\sum_{i \in I}-\log p_\theta\left(\tilde{x}_i \mid x_{1: L}\right)\right]}_{\text {masked language modeling }}+\underbrace{-\log p\left(c \mid \phi\left(x_{1: L}\right)_1\right)}_{\text {next sentence prediction }}
$$
RoBERTa
RoBERTa对BERT进行了以下改进:
- 删除了下一句预测这一目标函数(发现它没有帮助)。
- 使用更多数据训练(16GB文本 $\Rightarrow$ 160GB文本 )。
- 训练时间更长。
- RoBERTa在各种基准上显著提高了BERT的准确性(例如,在SQuAD上由81.8到89.4)。
Encoder-decoder 模型
T5 (Text-to_Text Transfer Transformer)
BART (Lewis et al. 2019)是基于Transformer的编码器-解码器模型。
- 使用与RoBERTa相同的编码器架构(12层,隐藏维度1024)。
- 使用与RoBERTa相同的数据进行训练(160GB文本)。
BART使用了以下变换 $A(\tilde x_{1:L} \mid x_{1:L})$ :
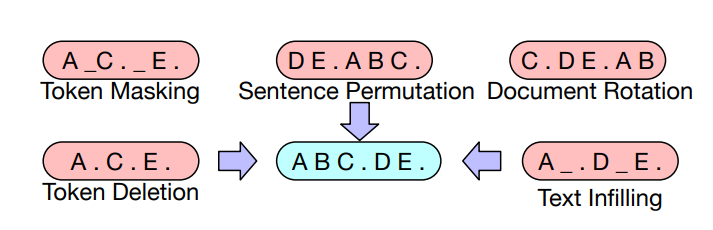
基于BERT的实验,最终模型进行以下了变换:
- 掩码文档中30%的token
- 将所有子句打乱
优化算法
都是见过的捏
Adaptation
就好像给南梁安一个♟️一样,他也是需要适应的。而♟️ 就是下游任务,适应就是Adaptation捏。主要有以下几个adaptation的方法捏
感觉都有点老了捏,就这样吧
后面就是马原部分了捏。先就这样了捏