self-llm Part 1 | Something about Qwen
感觉从 Qwen 是不是回方便一点捏
记录根据 self-llm 上的教程走一遍 Qwen 模型部署,微调等的流程。
部署和调用
md AutoDL怎么到现在了还是那种即贵又租不到的样子捏
无所谓,7B 的本地搞搞应该问题不大吧
整体上来说,就是用 modelscope 下好模型后用transformers包里的AutoTokenizer, AutoModelForCausalLM, GenerationConfig类调用
这三个类正是这一流程中的关键组件。AutoTokenizer 负责预处理和后处理,AutoModelForCausalLM 是模型主体,而 GenerationConfig 则精细控制模型推理的生成过程。
AutoTokenizer:数据清洗与编码/解码工具- 将文本编码为 Token ID (转为数字): 将字符串 split 不同的语义单位(tokens),然后利用词表,将这些 tokens 映射为模型预定义的整数 ID 序列。这是把非结构化文本数据“结构化”的第一步。
- 处理特殊 Token: 模型通常不仅使用词语,还使用具有特殊含义的 ID。
AutoTokenizer会自动添加例如:[CLS](分类特征前缀) 或<s>(句子开始)[SEP](句子分隔符) 或</s>(句子结束)[PAD](填充,用于将不同长度的输入补齐到相同长度,以便批处理)[UNK](未知词,把词表中没有的词标记为此)
- 创建 Attention Mask: 这是一个 0/1 的矩阵(或向量),告诉模型输入中的哪些位置是实际的 tokens(值为 1),哪些位置是填充补齐的无效内容(值为 0),以便模型在计算自注意力时忽略它们。
- 将 Token ID 解码回文本 (还原数据): 在模型生成文本后,将生成的整数 ID 序列还原为人类可读的字符串。
AutoModelForCausalLM:因果语言模型主体
这是模型本身的核心架构和预训练权重的加载器。同样,带有Auto前缀,它会自动根据你提供的模型 ID,确定它是 GPT 类型、Llama 类型还是其他类型的架构,并加载对应的具体模型类(例如,如果是 “gpt2”,它会加载GPT2LMHeadModel)。GenerationConfig:生成过程控制中心
用来系统地管理和定义这些决策逻辑的配置对象。它将这些控制参数从具体的生成调用中分离出来,使其可复用、可保存、可加载。
LoRA 微调
什么是LoRA
主要参考了知乎老哥
LoRA (Low-Rank Adaptation) 指在优化时利用秩更低的$\Delta W$更新训练参数,具体来说,假设权重更新的过程中也有一个较低的本征秩,对于预训练的权重参数矩阵 $W0 \in R^{d \times k}$ ($d$ 为上一层输出维度,$k$ 为下一层输入维度),使用低秩分解来表示其更新:
$$
W_0 + {\Delta}W = W_0 + BA \space\space where \space B \in R^{d \times r}, A \in R^{r \times k}
$$
在训练过程中,$W_0$冻结不更新,A、B 包含可训练参数。因此,LoRA 的前向传递函数为:
$$
h = W_0 x + \Delta W x = W_0 x + B A x
$$
在开始训练时,对 A 使用随机高斯初始化,对 B 使用零初始化,然后使用 Adam 进行优化。
训练思路如图:
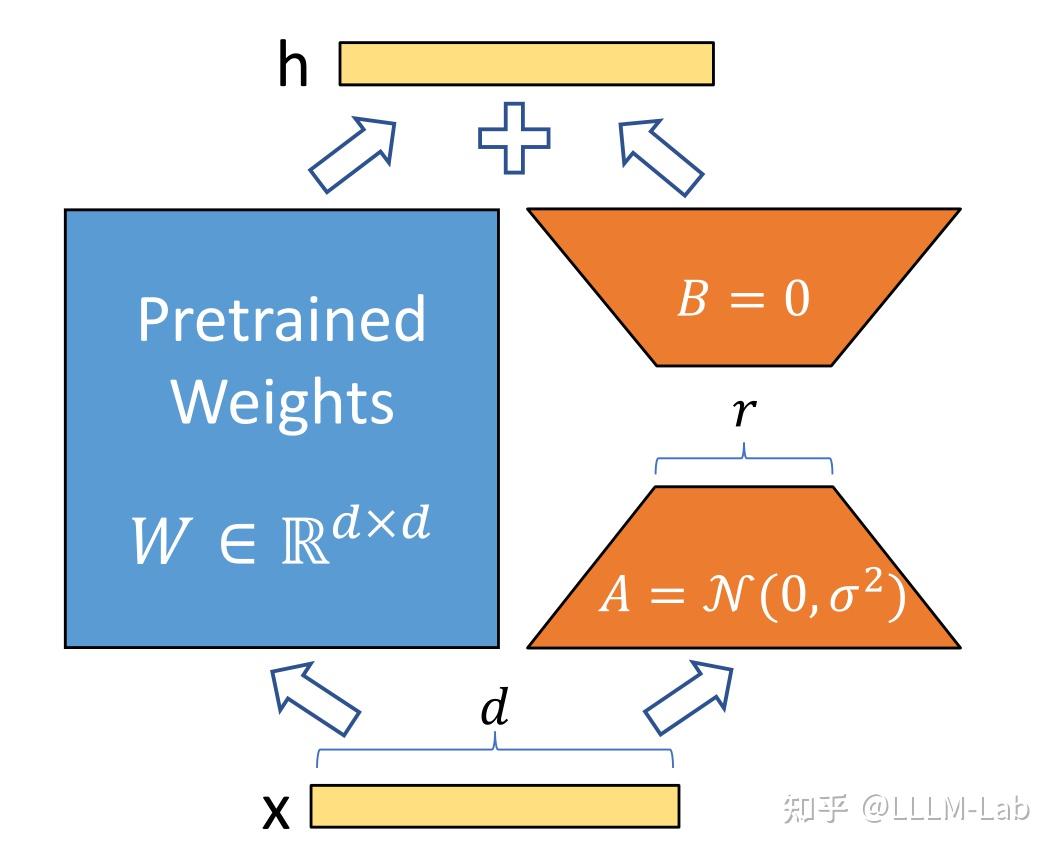
本质上来讲,LoRA是通过将参数限制在一个子空间内训练,来达到一个微调的效果
实现
感觉就是碉堡捏,所以以后的实现都不写了捏
P-tuning
核心概念:什么是“软提示” (Soft Prompts)?
在理解 P-tuning 之前,先要明确它的前身——提示工程 (Prompt Engineering)。
硬提示 (Hard Prompts) —— 人类的大白话
当我们使用 GPT 或者清华的 ChatGLM 进行任务时,我们会写很多指令:
“你现在是一名精通金融的数据分析师。请阅读以下文本,将所有提到的上市公司的净利润提取出来,并以 JSON 格式返回。文本内容:……”
这种通过人类自然语言编写,由一个一个具体词汇组成的提示,被称为 “硬提示” (Hard Prompts)。
- 它的局限性: “硬提示”很难设计,一个字的差别常常导致结果天差地别(提示工程是个细活)。而且输入模型的指令会占用模型的文本输入长度(Context Window),代价昂贵,且无法从根本上修改模型的内部表示。
P-tuning 的方法:软提示 (Soft Prompts) —— 模型的参数
P-tuning (Prompt Tuning) 的核心思想是:与其人工去找那些蹩脚的“硬提示”大白话,不如干脆让模型自己在高维向量空间里去“学习”一种特定的前缀指示。
这个“特定的前缀”不再是人类可读的文字(如“你是一个分析师”),而是几个可以被训练的、随机初始化的稠密向量 (Continuous Embedding Vectors),我们称之为 “软提示” (Soft Prompts) 或虚拟 Token (Virtual Tokens)。
P-tuning 的工作原理(数据分析师视角)
作为数据分析师,我们可以这样理解 P-tuning 的流程:
- 冻结 (Keep Frozen): 我们把巨大的预训练模型(如一个 175B 的模型)的所有原本参数全部冻结。在整个 P-tuning 过程中,这些参数都不会改变。意味着,你可以同时为 100 个不同的分析任务使用同一套冻结的模型基础。
- 添加 Soft Prompts: 在我们输入任务数据(比如公司的非结构化报告)的 Embedding 表示前面,拼接上几个(例如 20 个)专门为这个任务准备的 Soft Prompts 向量。
- 少量可训练参数: P-tuning 定义了一个非常小的、专门用于学习这些 Soft Prompts 向量的 “Prompt 编码器 / 优化器” (本质上是一个小的层,例如 LSTM 或 MLP,用于确保 Soft Prompts 在高维空间是连续稳定的)。
- 前向传递与反向传播:
- 输入流:
[Soft Prompts (可训练)] + [我们的报告数据 (冻结)]$\rightarrow$ LLM $\rightarrow$ 模型输出。 - 我们在特定数据集上进行训练。计算输出和真实标签(例如标准 JSON 格式)的误差。
- 在反向传播(训练)时,梯度只会传递并更新那几个 Soft Prompts 向量的参数,主模型的几千亿个参数巍然不动。
- 输入流:

为什么中断了捏
鼠鼠感觉这个项目更像一个字典,告诉你现有的开源大模型调用和调参的具体步骤。因此所有的项目都大同小异。
在了解基本的原理之后,感觉剩下就可以vibe了捏