so-large-lm | Ex. Mixture of Experts
Mixture of Experts
这是在看到so-large-lm第四章的时候,觉得MoE和RAG应该单独开一坨(而且可能还不太够捏。
这是MoE部分的内容,主要是鼠鼠在这几篇论文的笔记捏
什么是MoE
Mixture of Experts (MoE) 是一种通过牺牲“内存空间”来换取“计算效率”和“模型容量”的架构方案。它利用类似“专家分诊”的路由机制,实现了参数规模的指数级增长,同时保持了推理复杂度的线性增长。
开搓捏
Adaptive Mixtures of Local Experts
开山之作,但主要是思想主要是那个时候应该连深度学习都还不太流行吧
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
正式提出了MoE layer,但那个时候好像Transformer才出来捏。鼠鼠的第一次还是想给一个和Transformer结合的捏。
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
主要的目的是在牺牲内存占用的情况下,换取参数规模和计算效率
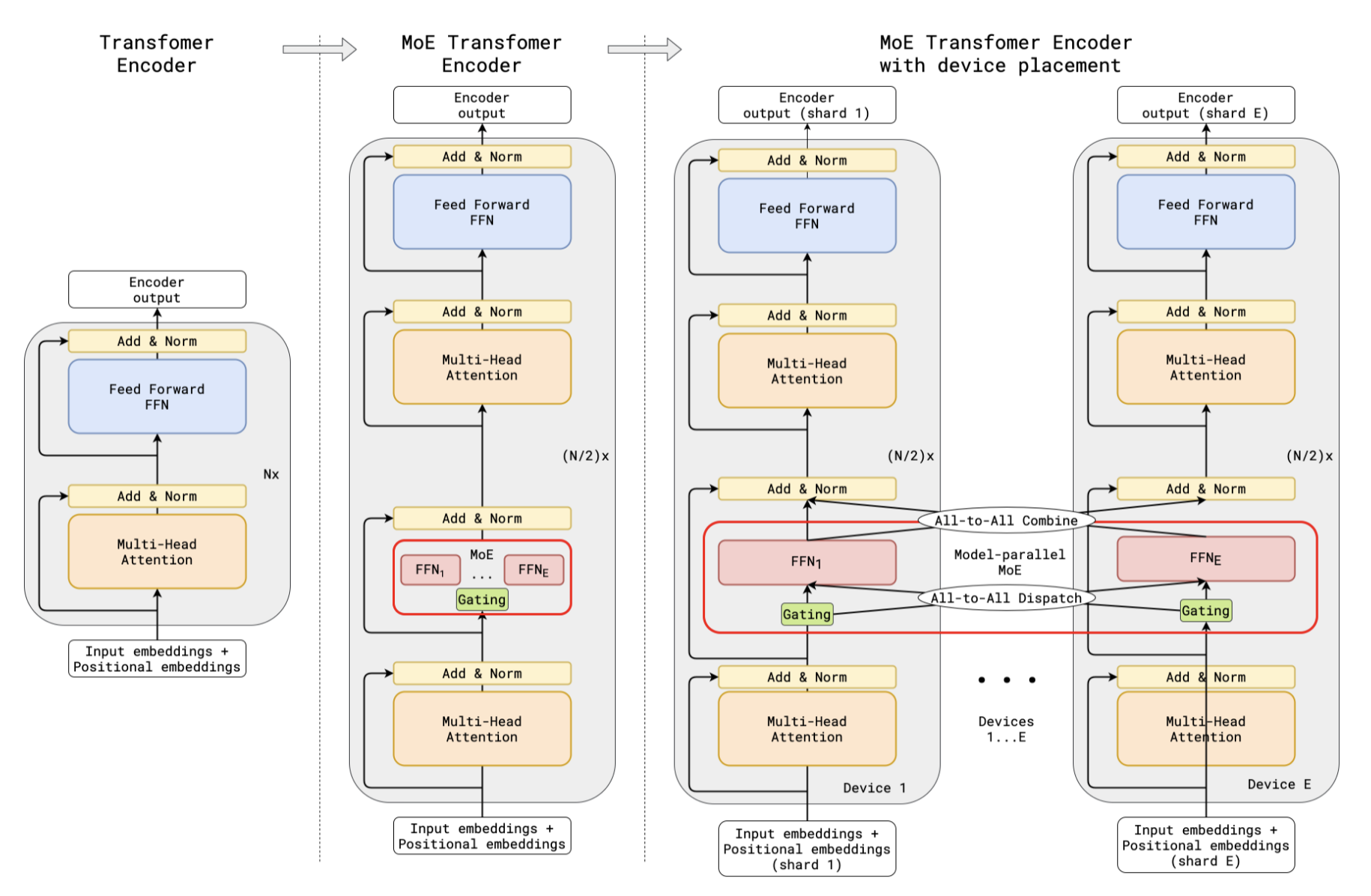
在这里,我们先将正常情况下FFN切分成多个小的FFN,每个FFN代表一个 Expert。然后,构建一个Router $G(x)$ 用于选择激活那些专家用于计算。
具体来说,文中选用了Top2的门就是一个门最多塞进两根,然后MoE层输出所选专家输出的加权和。
为了确保计算效率和负载均衡,GShard 引入了两个关键设计:
- 专家容量 (Expert Capacity):为了防止所有 token 都涌向同一个专家,每个专家处理的 token 数量被限制在一个阈值内。如果某个专家的 token 超过了容量限制,多余的 token 将通过残差连接直接跳过该层(即被视为“溢出”)。
- 辅助损失 (Auxiliary Loss):为了鼓励门控网络均匀地分配 token,模型在训练时加入了一个辅助损失函数。
贴一个源代码方便理解捏:

Towards Crowdsourced Training of Large Neural Networks using Decentralized Mixture-of-Experts
提出了一种提出去中心化专家混合模型(DMoE),提出可以在不同的设备里同时做MoE(感觉是一个偏工程的东西捏
BASE Layers: Simplifying Training of Large, Sparse Models
Balanced assignment of sparse experts (BASE)将近似门控函数 $\tilde g(x)$ 定义为对batch中的所有token进行联合优化的结果。对于每一个训练的batch
为每个token分配1名专家,但负载平衡是一种约束,而不是软惩罚
定义 $a = [a_1, \dots, a_B] \in {1, \dots, E}^B$ 作为联合分配向量
$$
\text{maximize} \sum_{i = 1}^B w_{a_i} \cdot x_i \quad\text{subject to}\quad \forall e: \sum_{i=1}^B \mathbf{1}[a_i = e] = \frac{B}{E}.
$$
- 这是一个可以有效求解的线性方程
- 在测试时,只需选择top 1的专家即可
堡堡只能🍵一根捏。
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
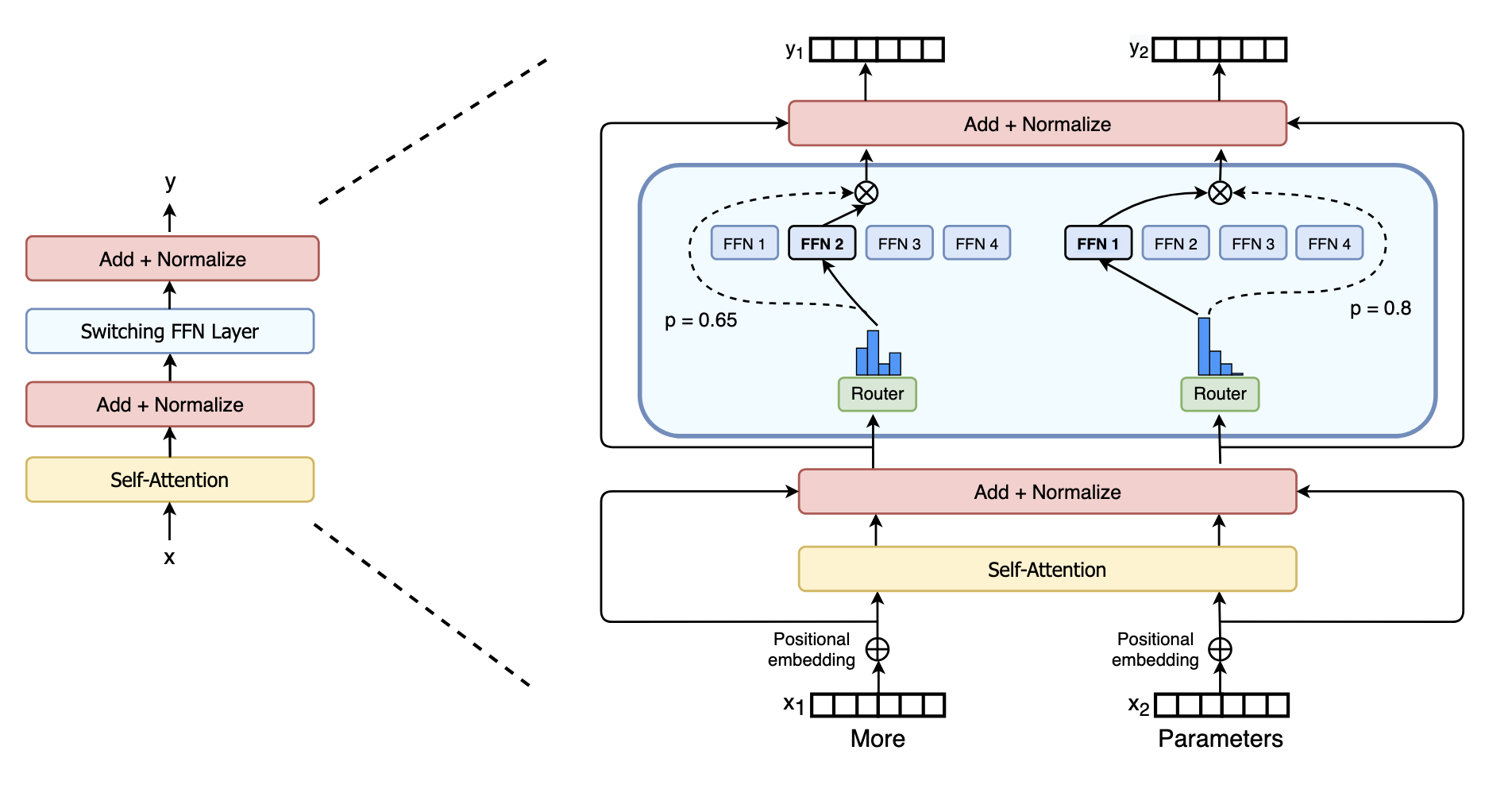
简化了先前的工作,现在的门只能入一根了捏
此外,提出了更加详细的模型容量的计算方式,很好理解,鼠鼠直接就是一个图的丢捏
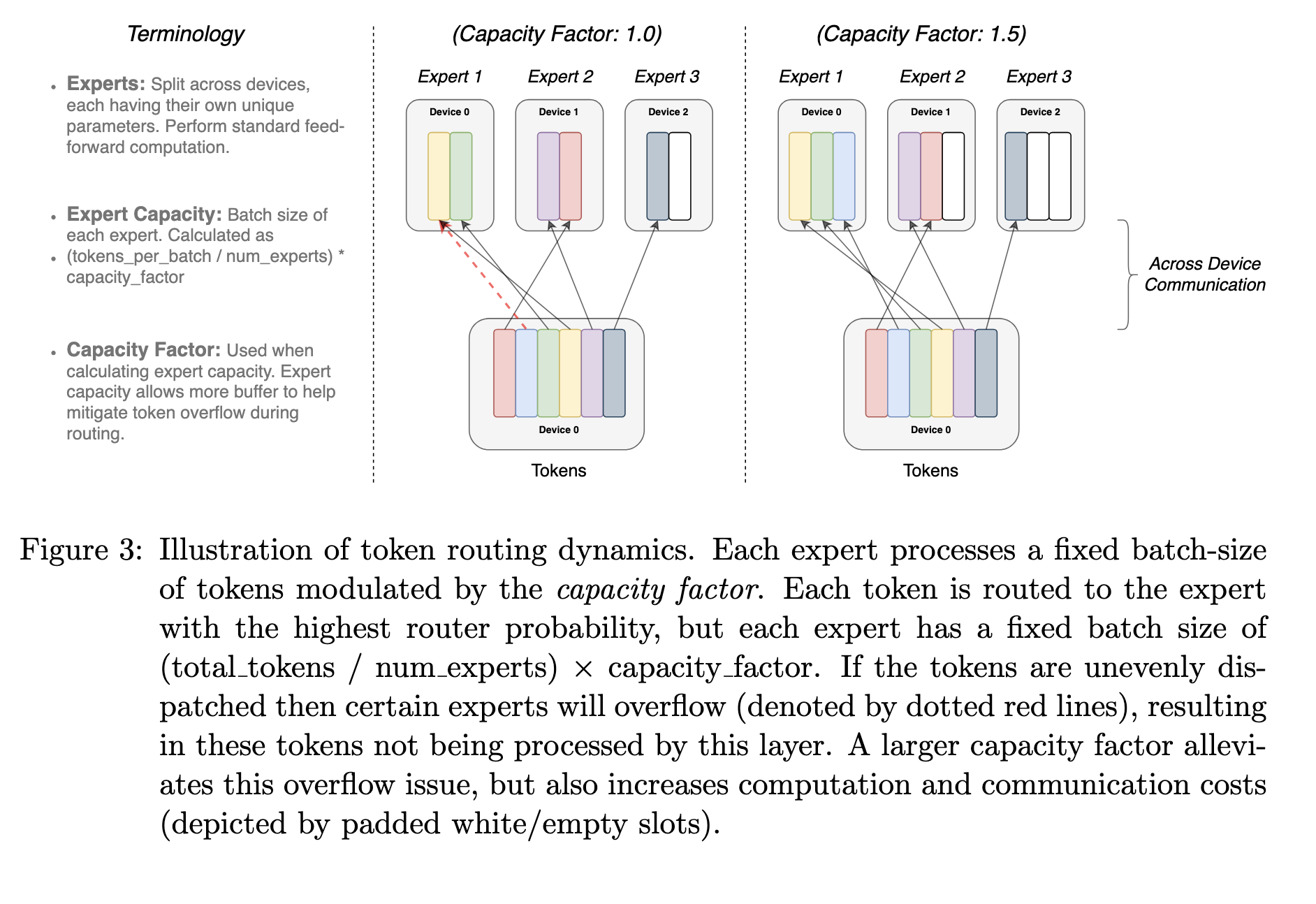
实验:GieGie动🉐真是又大💗又快💗捏
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- 构建了一个Fine-grained expert segmentation,就是多大的门🍵多少根💗捏
- 一个Shared expert,不受router控制
emmm,感觉差不多了捏(主要是吃不动了捏